 I’m in the final stretch of the OER Visualisation project. Recently reviewing the project spec I’m fairly happy that I’ll be able to provide everything asked for. One of the last things I wanted to explorer was automated/semi-automated programme reporting from the PROD database. From early discussions with CETIS programme level reporting, particularly of technology and standards used by projects, emerged as a common task. CETIS already have a number of stored SPARQL queries to help them with this, but I wondered if more could be done to optimise the process. My investigations weren’t entirely successful, and at times I was thwarted by misbehaving tools, but I thought it worth sharing my discoveries to save others time and frustration.
I’m in the final stretch of the OER Visualisation project. Recently reviewing the project spec I’m fairly happy that I’ll be able to provide everything asked for. One of the last things I wanted to explorer was automated/semi-automated programme reporting from the PROD database. From early discussions with CETIS programme level reporting, particularly of technology and standards used by projects, emerged as a common task. CETIS already have a number of stored SPARQL queries to help them with this, but I wondered if more could be done to optimise the process. My investigations weren’t entirely successful, and at times I was thwarted by misbehaving tools, but I thought it worth sharing my discoveries to save others time and frustration.
My starting point was the statistical programming and software environment R (in my case the more GUI friendly RStudio). R is very powerful in terms of reading data, processing it and producing data analysis/visualisations. Already CETIS’s David Sherlock has used R to produce a Google Visualisation of Standards used in JISC programmes and projects over time and CETIS’s Adam Cooper has used R for Text Mining Weak Signals, so there is some in-house skills which could have built on this idea.
Two other main factors for looking at R as a solution are:
- the modular design of the software environment makes it easy to add functionality through existing packages (as I pointed out to David there is a SPARQL package for R which means he could theoretically consume linked data directly from PROD); and
- R has a number of ways to produce custom reports, most notably the Sweave function allows the integration of R output in LaTeX documents allowing the generation of dynamic reports
So potentially a useful combination of features. Lets start looking at some of the details to get this to work.
Getting data in
Attempt 1 – Kasabi custom API query
Kasabi is a place where publishers can put there data for people like me to come along and try and do interesting stuff with it. One of the great things you can do with Kasabi is make custom APIs onto linked data (like this one from Wilbert Kraan) and add one of the Kasabi authored XSLT stylesheets to get the data returned in a different format, for example .csv which is easily digestible by R.
Problem: Either I’m doing something wrong or there is an issue with the data on Kasabi or an issue with Kasabi itself because I keep getting 400 errors on queries I know work like this OER Projects with location but not when converted to an API
Attempt 2 – Query the data directly in R using the SPARQL package
As I highlight to David there is a SPARQL package for R which in theory lets you construct a query in R, collect the data and put it in a data frame.
Problem: Testing the package with this query returns:
Error in data.frame(projectID = c(1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, : arguments imply differing number of rows: 460, 436, 291, 427, 426
My assumption is the package doesn’t like empty values.
Attempt 3 – Going via a sparqlproxy
For a lot of the other PROD SPARQL work I’ve done I’ve got csv files by using the Rensselaer SPARQL proxy service. R is quite happy reading a csv via the proxy service (code included later), it just means you are relying on an external service, which isn’t really necessary as Kasabi should be able to do the job and it would be better if the stored procedures were in one place (I should also say I looked at just using an XML package to read data from Talis/Kasabi but didn’t get very far.
Processing the data
This is where my memory gets a little hazy and I wished I took more notes of the useful sites I went to. I’m pretty sure I got started with Tony Hirst’s How Might Data Journalists Show Their Working? Sweave, I know also that I looked at Vanderbilt’s Converting Documents Produced by Sweave, Nicola Sartori’s An Sweave Tutorial, Charlie Geyer’s An Sweave Demo Literate Programming in R Reproducible Research, Greg Snow’s Automating reports with Sweave and Jim Robison-Cox’s Sweave Intro (this one included instructions on installing the MikTeX latex engine for windows which with out none of this would had worked).
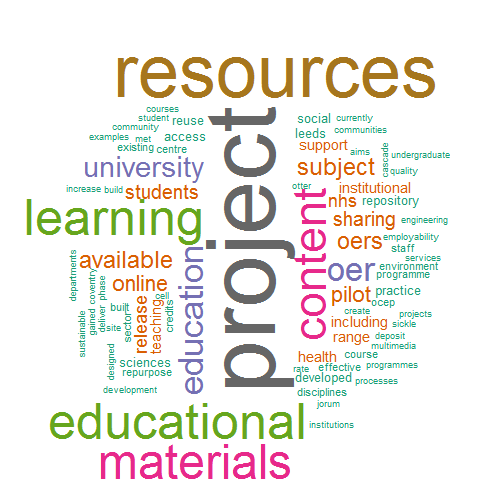
The general idea with R/Sweave/LaTeX is you markup a document inserting R script which can be executed to include data tables and visualisations. Here’s a very basic of an output (I think I’ve been using R for a week now so don’t laugh) example which pulls in two data sets (Project Descriptions | Project Builds On), includes some canned text and generates a wordcloud from project descriptions and a force directed graph of project relationships.
The code used do this is embedded below (also available from here):
The main features are the \something e.g. \section which is LaTeX markup for the final document and the <<>>= and @ R script code wrappers. I’ve even less experience of LaTeX than R so I’m sure there are many things I don’t know yet/got wrong, but hopefully you can see the potential power of the solution. Things I don’t like are being locked into particular LaTeX styles (although you can create your own) and the end product being a .pdf (as Sweave/R now go hand in hand a lot of the documentation and coding examples end up in .pdf which can get very frustrating when you are trying to copy ad paste code snippets, which also makes me wonder how accessible/screen reader friendly sweave/latex pdfs are).
Looking for something that gives more flexibility in output I turned to R2HTML which includes “a driver for Sweave allows to parse HTML flat files containing R code and to automatically write the corresponding outputs (tables and graphs)” . Using a similar style of markup (example of script here) we can generate a similar report in html. The R2HTML package generates all the graph images and html so in this example it was a case of uploading the files to a webserver. Because it’s html the result can easily be styled with a CSS sheet or opened in a word processor for some layout tweaking (here’s the result of a 60 second tweak.
Is it worth it?
After a day toiling with SPARQL queries and LaTeX markup I’d say no, but its all very dependant on how often you need to produce the reports, the type of analysis you need to do and your anticipated audience. For example, if you are just going to present wordclouds and histograms R is probably overkill and it might be better to just use some standard web data visualisation libraries like mootools or Google Visualisation API to create live dashboards. Certainly the possibilities of R/Sweave are worth knowing about.
Sheila MacNeill
Another great post, Martin. Thanks for the updates, I do feel over the past couple of weeks the stuff you and David have been doing is really helping us to focus on what kind of outputs are useful and that we really need, so we can then start focusing on finding some quick wins for mere mortals like me to do something with the data.
S
OER Visualisation Project: Fin [day 40.5] – MASHe
[…] that were produced include: OER Phase 1 and 2 maps [day 20], timelines [day 30], wordclouds [day 36] and project relationship [day 8] Recommendations on use and […]